SEO – manuál pro vývojáře
Analytické nástroje
Google Analytics
Google Analytics je užitečná služba sloužící k monitoringu návštěv, které proudí na web z různých kanálů. Standardem byla verze nazývaná jako Universal Analytics. Google však tuto verzi bude vypínat k 1. 7. 2023 a je tak nutné mít nasazenou i novou verzi Google Analytics 4. Google Analytics je třeba nasadit na každou novou webovou službu.
Více o postupu nasazení Google Search Console naleznete v oficiálních dokumentech pro vývojáře.
Google Search Console
Google Search Console je nástroj sloužící pro vyhodnocování úspěšnosti v přirozených výsledcích vyhledávání vyhledávače Google. Poskytuje důležité metriky, jako je počet prokliků na web, počet impresí ve výsledcích vyhledávání, CTR a průměrná pozice. Tyto metriky je možné sledovat na úrovni klíčového slova i vstupní stránky. Google Search Console je stejně jako Google Analytics třeba nasadit na každou novou webovou službu.
Doporučené je ověření nástroje na úrovni celé domény prostřednictvím DNS záznamů. Následně je pro přesnost statistik užitečné založit samostatný účet pro každou důležitou subdoménu, která na dané doméně běží.
Více o postupu nasazení Google Search Console naleznete v oficiálních dokumentech pro vývojáře.
Direktivy a meta tagy v hlavičce HTML dokumentu
Direktivy a meta tagy v hlavičce HTML dokumentu slouží k předání informací o relacích stránek mezi sebou (Canonical, Hreflang, stránkování) a k pokynům pro vyhledávače ohledně indexace a procházení dané stránky ((No)Index, (No)Follow).
Direktiva Meta Robots - (No)index, (no)follow
V direktivě Meta Robots vyhledávači říkáme, zda stránku má procházet a indexovat. Výchozí stav je:
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="index, follow" />
…
</head>
<body>…</body>
</html>Direktiva follow/nofollow v atributu content vyhledávači říká, zda má následovat odkazy umístěné na této stránce. Direktiva index/noindex potom vyhledávači říká, zda tuto stránku má indexovat a následně zobrazovat ve výsledcích vyhledávání. Pokud bychom tedy stránku z nějakého důvodu ve výsledcích vyhledávání zobrazovat nechtěli, vypadal by zápis takto:
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
…
</head>
<body>…</body>
</html>Pokud bychom chtěli, aby vyhledávač následoval odkazy na stránce, ale neindexoval ji, zápis by vypadal takto:
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex, follow" />
…
</head>
<body>…</body>
</html>Více o tomto nastavení můžete dozvědět v Google nápovědě pro vývojáře.
(Self)canonical
Dalším důležitým nastavením v rámci meta tagů v hlavičce HTML je kanonizace. Primárně slouží k tomu, aby se mezi dvěma obsahově identickými stránkami rozlišilo, která z nich má pro vyhledávač sloužit jako obsahový originál. Zápis na stránce s duplicitním obsahem může vypadat následovně:
<!DOCTYPE html>
<html>
<head>
<link rel="canonical" href="https://domena.cz/original/" />
…
</head>
<body>…</body>
</html>Jelikož jsou pro vyhledávač obsahově identickými stránky například i:
- domena.cz/stranka/
- domena.cz/stranka/?utmparametr=1
- domena.cz/stranka/?fbclid=hash
- domena.cz/stranka/#kotva
Je důležité i u těchto stránek rozlišit, která z verzí je originální. Tyto všechny stránky bychom kanonizovali na čistou verzi bez parametrů a kotev v URL. Hovoříme o tzv. selfcanonical:
<!DOCTYPE html>
<html>
<head>
<link rel="canonical" href="https://domena.cz/stranka/" />
…
</head>
<body>…</body>
</html>Self-canoncial je best practice a měl by být používán automaticky na všech stránkách webu. Důsledkem self-canonical zápisu je to, že stránka, na kterou jsou ostatní stránky kanonizovány, defakto přejímá sílu (Link juice) všech těchto stránek.
Více o nastavení canonical elementu se dozvíte v nápovědě Google.
Hreflang
Pokud jsou stránky ve více jazykových verzích je nutné vyhledávači v hlavičce HTML dokumentu namapovat ostatní jazykové analogy. Vyhledávači to pomůže lépe porozumět relaci daných stránek a nabízet správné jazykové země občanům daných států. Zároveň má tento zápis příznivý dopad také na indexaci všech jazykových verzí obecně.
<!DOCTYPE html>
<html>
<head>
<link rel="alternate" hreflang="cs-CZ" href="https://www.domena.cz/cs/" >
<link rel="alternate" hreflang="sk-SK" href="https://www.domena.cz/sk/" >
<link rel="alternate" hreflang="en-GB" href="https://www.domena.cz/en/" >
…
</head>
<body>…</body>
</html>Více o Hreflangu v hlavičce HTML naleznete opět v oficiální nápovědě Google.
Stránkování
Dříve potřeboval Google k rozpoznání stránkovaného obsahu specifikovat v hlavičce HTML dokumentu meta tagy <link rel="prev" href=""> a <link rel="next" href="">, což je dnes již postup, který vyhledávač pro identifikaci stránkování nepoužívá. Důležité v rámci stránkovaného obsahu je následující:
- Stránky by měly mít tlačítka "předchozí" a "další" (konkrétní slova nejsou důležitá je možné použít synonyma).
- V parametru URL stránky musí být identifikovány číslem.
- Každá stránka stránkování by měla mít svůj self-canonical. Kanonizovat všechny stránky v rámci stránkování na tu první (hlavní) je chyba! Je to proto, že jednotlivé stránky se obsahově liší a tudíž kanonizace nedává smysl.
- Pokud nechceme nechat stránkovaný obsah indexovat můžeme na druhé a další stránce použít direktivu noindex,follow:
<meta name="robots" content="noindex, follow" />
Soubory v kořenovém adresáři webu (robots.txt a sitemap.xml)
Soubory sitemap.xml a robots.txt vyhledávači říkají, jak se má na webu chovat. Které stránky procházet a indexovat, a kterým se vyhnout.
Sitemap.xml
Soubory sitemap.xml umožňují informovat vyhledávače o URL adresách webu, které jsou k dispozici pro procházení a indexaci. Tyto soubory jsou vytvořeny ve formátu XML, ve kterém jsou strukturovaně uvedeny URL adresy podstránek webu s dalšími atributy. Tyto atributy umožňují předávat vyhledávačům další informace jako datum poslední aktualizace stránky (lastmod), jak často se mění (changefreq) a jakou má relativní důležitost vůči ostatnímu obsahu na webu (priority). Všechny tyto atributy jsou volitelné a nijak neovlivňují pozice ve výsledcích vyhledávání. Jejich uvedením pouze umožňujete vyhledávačům procházet web inteligentnějším způsobem a soustředit se na obsah, který je skutečně podstatný.
Kód souboru sitemap.xml může vypadat následovně. Zde je ukázka nejjednoduššího souboru sitemap.xml, kterou tvoří jeden odkaz:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/</loc>
<lastmod>2017-09-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>V XML kódu souboru sitemap.xml se mohou vyskytovat následující tagy:
<urlset>– povinný tag, který obaluje celý kód a odkazuje se na referenční standard pro soubor sitemap.xml.<url>– povinný tag, který obaluje kód pro každou URL webu.<loc>– povinný tag, ve značkách<loc>se nachází URL adresy webu, který požadujete po robotovi projít a indexovat.<lastmod>– nepovinný tag, ve kterém vyhledávači říkáte, kdy byla stránka naposledy změněna, udává se ve formátu YYYY-MM-DD.<changefreq>– nepovinný tag, který udává, jak často se stránka v průměru mění, může nabývat několika předdefinovaných hodnot: always, hourly, daily, weekly, monthly, yearly, never.<priority>– nepovinný tag, který určuje prioritu dané podstránky webu, může nabývat hodnot od nuly do jedné, kdy 0.0 symbolizuje nejnižší prioritu a 1.0 nejvyšší.
Tagy <changefreq> a <priority> roboti vyhledávačů dost pravděpodobně úplně ignorují, takže není nutné je do souboru sitemap.xml propisovat.
Soubory sitemap by měly být generovány dynamicky přímo na serveru. Tedy jakmile vznikne nová stránka, měla by být do souboru sitemap.xml přidána.
Na kontrolu správnosti souboru sitemap.xml existuje řada nástrojů. Nejsnazší je ovšem provést validaci přímo v nástroji Google Search Console.
A jak se Google o souboru sitemap.xml dozví? Je třeba tomu jít trochu naproti tím, že:
- Soubor sitemap.xml umístíme do kořenového adresáře webu. Bude tedy na adrese, která odpovídá vzoru https://domena.cz/sitemap.xml.
- Soubory sitemap.xml nahrajeme do nástroje Google Search Console.
- Odkaz na soubor sitemap.xml umístíme do souboru robots.txt (viz níže).
Nejčastější chyby při tvorbě souboru sitemap.xml:
- absence důležitých URL stránek, které chceme indexovat vyhledávači,
- výskyt URL stránek, které jsou přesměrované na jinou stránku,
- výskyt URL stránek, které vracejí stavový kód 404 nebo 410,
- výskyt URL stránek, které jsou kanonizované na jinou stránku,
- výskyt URL stránek s meta robots nebo x-robots noindex.
Komprese a rozdělení souboru sitemap.xml
Nezkomprimovaná velikost souboru sitemap.xml by podle doporučení Google i Seznamu neměla přesáhnout 50 MB nebo 50 tisíc URL. V případě, že je velikost větší, doporučují se obecně následující řešení: Soubor sitemap.xml rozdělit na více menších a z URL sitemap.xml na ně odkazovat (viz sitemap index). Zkomprimovat soubor sitemap.xml do formátu GZip. Obě metody se dají kombinovat. Z jednoho sitemap indexu tak může vést odkaz na více souborů sitemap.xml zkomprimovaných metodou GZip.
Robots.txt
Robots.txt funguje opačným způsobem než sitemap.xml. Můžete v něm zamezit vstupu robotů vyhledávačů na určité části webu. Jedná se o globální standard, který je určen především pro roboty vyhledávačů, aby na webu neprováděly akce, které jsou nežádoucí. Správnou specifikací tak můžete zamezit procházení nedůležitých nebo duplicitních URL vašeho webu (např. URL s parametry apod.).
Tento soubor vyhledávače vždy načítají jako první, pak procházejí další stránky webu. Soubor robots.txt by měl být vždy pojmenován jako „robots“ a měl by být umístěn v kořenovém adresáři domény, tedy např. http://www.example.com/robots.txt.
Kód souboru robots.txt může vypadat následovně:
User-agent: *
Disallow: /admin/
Sitemap: http://www.example.com/sitemap.xmlNapříklad tento kód říká, že roboti mohou web procházet bez omezení s výjimkou složky /admin/ a jejích podadresářů.
Správnost nastavení souboru robots.txt je možné otestovat v nástroji testing tool in Google Search Console.
Obrázky
U obrázků je z pohledu SEO důležitá jejich informační hodnota i vliv na rychlost načítání webové stránky. Informační stránka je daná hlavně atributem alt a textem, který obrázek obklopuje. U vlivu na rychlost načítání webové stránky hrají hlavní roli formát a velikost (jak ta v KB, tak ta v rozměrech v pixelech). Velké obrázky mohou výrazně zpomalit načítání webu a pokud nejsou ve zdrojovém kódu definované jejich rozměry, mohou způsobovat také posuny obsahu během načítání (Cumulative Layout Shift - CLS).
Atribut alt
Atribut alt má funkci alternativního textu pro obrázek, pokud se obrázek nenačte. Pro vyhledávač poskytuje užitečnou textovou informaci o tom, co na obrázku je. Atribut alt by měl vyplňovat ten, kdo edituje obsah, nicméně vývojář by se měl postarat o to, aby zde pokud není alt atribut ručně vyplněn, existoval nějaký fallback. Tedy například, aby v alt atributu obrázku byl vyplněn název stránky (viz obrázek).
<img src="epetice.jpg" alt="ePetice">Formát WebP
Google uvádí jako ideální formát pro obrázky formát WebP, který je oproti formátu JPEG o 25–35 % menší, oproti formátu PNG až o 80 % menší.
O převodu obrázků do formátu WebP se více píše na oficiální nápovědě Google.
Specifikace velikosti prvků v HTML
Cumuated Layout Shift (CLS) je metrika, která výrazně ovlivňuje uživatelský dojem ze stránky. Zároveň je součástí měření Google Pagespeed Insights. Předejít velkému množství posunů v obsahu při načítání stránky pomůže, pokud se ve zdrojovém kódu explicitně specifikuje, jak velké jsou načítané prvky. Tedy specifikace atributů width a height u prvku IMG.
<img width=”300” height=”500” src=”obrazek.jpg”>Rychlost webu
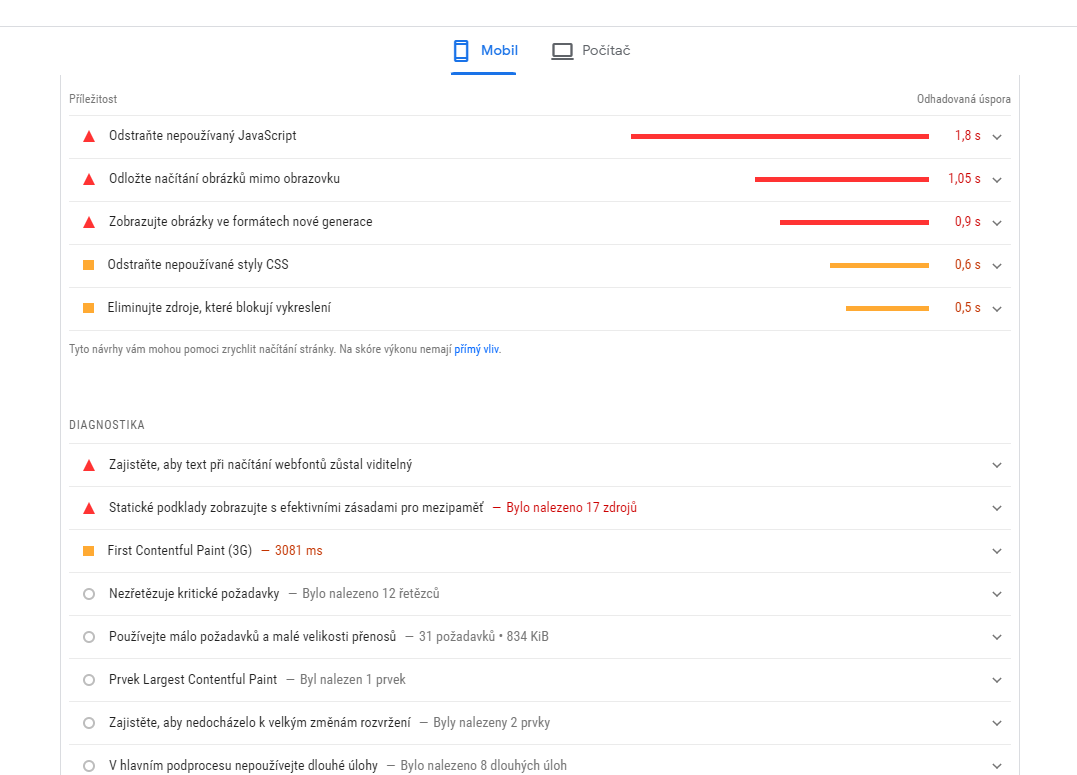
Doba načítání webu je důležitá jak pro uživatele, tak pro internetové vyhledávače. V rámci vyhledávání Google je rychlost načítání jedním z faktorů, které ovlivňují, jak vysoko se stránka zobrazí. Základním nástrojem pro optimalizaci rychlosti načítání webu je nástroj Google Pagespeed Insights.
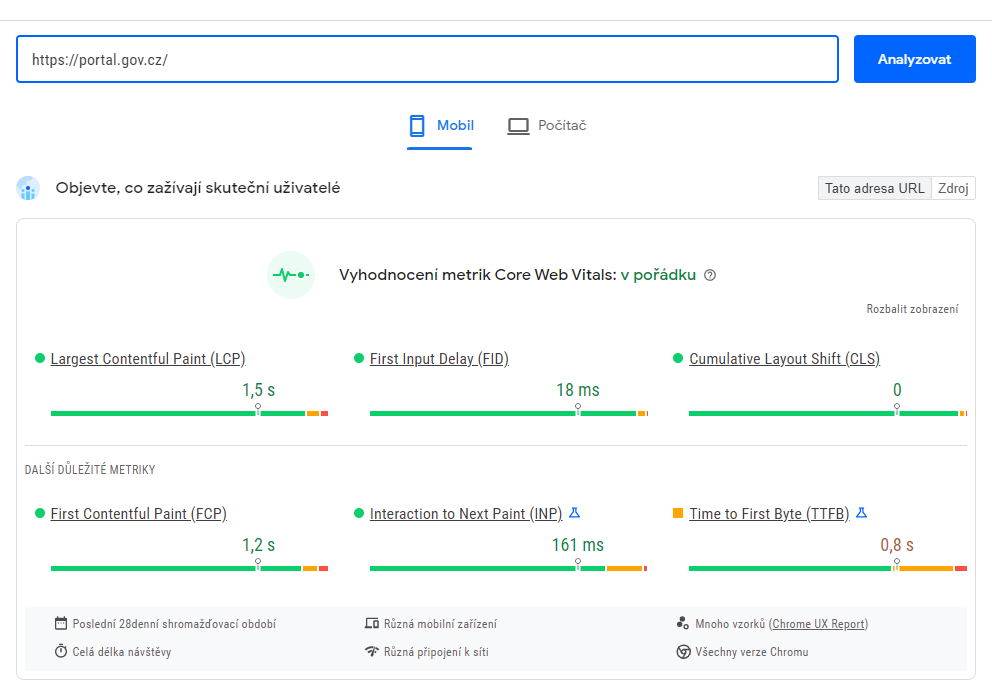
Hlavní metriky pro měření rychlosti stránek (Google Pagespeed Insights):
Largest Contetful Paint (LCP)
Doba vykreslení největšího obsahu. Udává, jak dlouho od žádosti uživatele o adresu URL trvalo vykreslení největšího obsahového prvku viditelného ve viewportu. Největším prvkem je obvykle obrázek nebo video, někdy jím však může být i velký textový blok. Vykreslení tohoto prvku je důležité, protože podle něj uživatel pozná, že se adresa URL opravdu načítá.
First Input Delay (FID)
Prodleva prvního vstupu. Doba od první interakce uživatele se stránkou (např. kliknutí na odkaz, klepnutí na tlačítko apod.) do okamžiku, kdy prohlížeč na danou interakci reaguje. Tento údaj se měří podle libovolného interaktivního prvku, na který uživatel kliknul jako první. Tento údaj je důležitý u stránek, na nichž uživatel musí něco provést. Od tohoto okamžiku totiž stránka začíná být interaktivní.
Cumulative Layout Shift (CLS)
Kumulativní změna rozvržení. CLS představuje součet všech jednotlivých skóre změny rozvržení pro všechny neočekávané změny rozvržení během celé doby existence stránky. Skóre může být libovolné kladné číslo nebo nula. Nula znamená, že se rozvržení stránky nemění, a čím je číslo vyšší, tím se rozvržení stránky mění více. Tento údaj je důležitý, protože pokud se prvky na stránce přesouvají, když se je uživatel pokouší používat, nepůsobí to dobře. Pokud je hodnota vysoká a nedaří se vám zjistit proč, zkuste se stránkou interagovat a sledujte, jaký to má na skóre vliv.
FIrst Contentful Paint (FCP)
První vykreslení obsahu. Doba, než se vykreslí první text nebo obrázek.
Time to First Byte (TTFB)
Doba do načtení prvního bajtu. Doba do načtení prvního bajtu HTML webu.
Google Pagespeed Insights vám řeknou, v jaké z těchto hlavních metrik rychlosti načítání web zaostává a jaké jsou konkrétní možnosti zlepšení.
Strukturovaná data
Strukturovanými daty můžeme vyhledávači předat více informací o obsahu stránky. Ta pak může být lépe dohledatelná a zároveň se může zobrazit v tzv. Rozšířených výsledcích vyhledávání. Takovými rozšířenými výsledky může být například drobečková navigace ve snippetu ve výsledcích vyhledávání, hvězdičkové hodnocení pod výsledkem vyhledávání nebo často kladené otázky (FAQ).
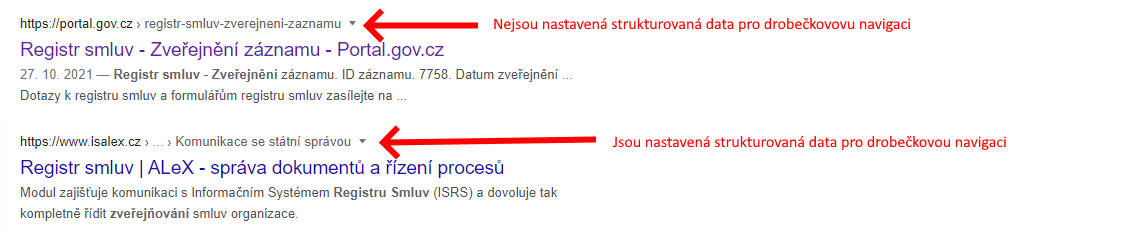
Strukturovaná data pro vyhledávače vychází ze standardu Schema.org. Přestože je formátů, jakými je možné strukturovaná data podle Schema.org implementovat více, Google podporuje nejvíce JSON-LD. Tedy JSON Linked Data, což je formát, který je přehledný a pro implementaci standardu schema.org ideální. Zdrojový kód ve formátu JSON-LD pro drobečkovou navigaci by mohl vypadat například takto:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [{
"@type": "ListItem",
"position": 1,
"name": "Úvod",
"item": "https://portal.gov.cz/"
}, {
"@type": "ListItem",
"position": 2,
"name": "Životní události",
"item": "https://pruvodce.gov.cz/"
}, {
"@type": "ListItem",
"position": 3,
"name": "Narození dítěte"
}]
}
</script>Formáty, které by z pohledu státní správy mohli dávat smysl:
- Drobečkovka (Všude)
- Sitelink Searchbox (Všude)
- Article (Jen konkrétní obsah)
- Event (Jen konkrétní obsah)
- Fact Check (Jen konkrétní obsah)
- Q&A (Jen konkrétní obsah)
- Video (Jen konkrétní obsah)
Strukturovaná data a jejich přítomnost na libovolné stránce lze otestovat v nástroji validator.schema.org.
Podobu strukturovaných dat ve výsledcích vyhledávání (Rich results) lze otestovat v nástroji search.google.com/test/rich-results.